JSALT 2015
JSALT 2015 Research
JSALT Main Page > Speech & NLP Summer School | Research Groups
Participant Information > Accommodations | Dining & Groceries | Transportation & Tourist Attractions
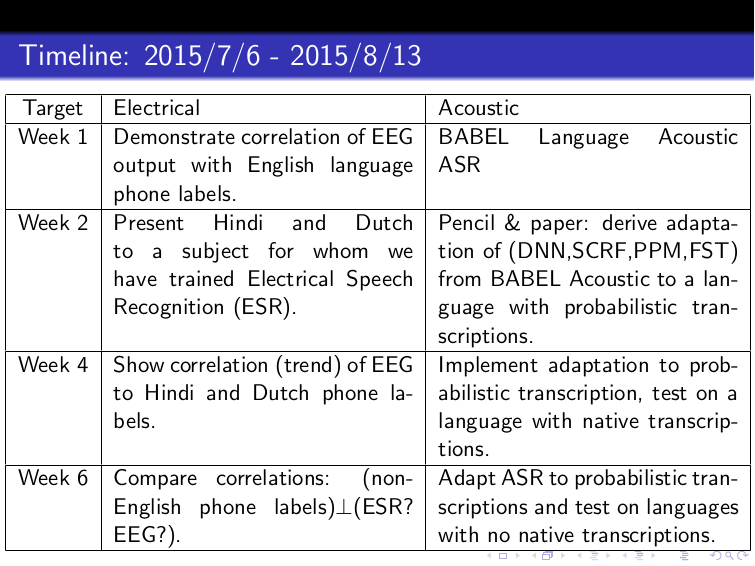
Project Overview: Probabilistic Transcription of Languages with No Native-Language Transcribers
Automatic speech recognition technology in smart phone personal assistants engages many users around the world. However, this technology is limited to a very small subset of the world’s languages, primarily due to the lack of availability of transcribed speech in most languages. The main bottleneck is limited access to native speakers of these languages. In this workshop, we propose to build techniques for generating speech transcripts in various languages without involving native-language transcribers at all! We seek to devise techniques to transcribe speech in a new language by combining information from three different sources: 1) mismatched ASR systems initially trained in a well-labeled language (e.g., English); 2) mismatched crowdsourcing wherein we use platforms such as Amazon’s Mechanical Turk to employ online workers who don’t speak the language to transcribe it; and 3) measurements of electrical activity in the brain (measured by electroencephalography or EEG) of humans who don't speak the language as they listen to speech in that language. Active learning will be used to select data for transcription so as to maximize the information learned in the human transcription process.